 I recently attended an International Forum for Visual Practitioners (IFVP) annual conference. Many of the participants were Graphic Recorders - people that record conversations and events visually (I highly recommend looking up the examples in the directory if you've never seen this type of work before).
I recently attended an International Forum for Visual Practitioners (IFVP) annual conference. Many of the participants were Graphic Recorders - people that record conversations and events visually (I highly recommend looking up the examples in the directory if you've never seen this type of work before).From speaking to other facilitators and watching the event unfold, I realized that the skills needed for recording are often different than those needed for graphic facilitation or communication. Many of the conversations I had at the conference centered on trying to better understand those differences.
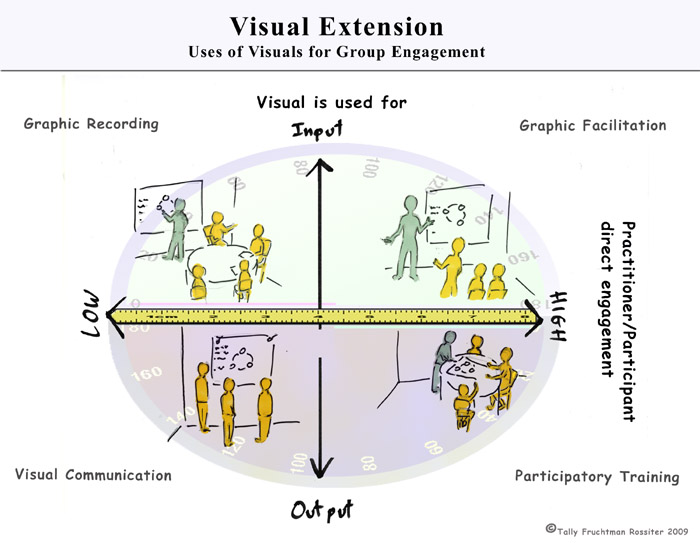
The Visual Extension model and structure for this blog will try to further explore the differences in tool usage and skills needed by visual practitioners depending on the type of work they are doing.
So what is the model about?
1. Practitioner/Participant Direct Engagement

The degree of participation we practitioners working with visuals have with their audience varies. It seems to me like the range moves from:
- Visual practitioners creating articles (murals, posters, books or designs) with little or no interaction with the audience. The Audience interacts personally with the visual but cannot change it.
- To more interactive participation like the audience’s manipulation of the visual itself (infographics) or the use of the visual to manage of the audience (when an image is used to affect the conversation/mood of the room – color, shocking concept).
- To direct engagement between the practitioner, audience, and image to manipulate the image.
 The second piece to the model is Output vs. Input - and what visuals are used for. Getting information out of people’s head (Input) is different than transmitting information into people’s heads (Output). An post from a VizThink forum addresses this question. Jeff Bennett created his own model to explain how information is transmitted.
The second piece to the model is Output vs. Input - and what visuals are used for. Getting information out of people’s head (Input) is different than transmitting information into people’s heads (Output). An post from a VizThink forum addresses this question. Jeff Bennett created his own model to explain how information is transmitted.How visuals are used varies by the goal – when getting input, the focus is on getting attention, organizing, getting participation, and boiling down information. When transmitting information to others, the focus is on how to help the person get interested and interact with the visual, “read” the message, and reach the “right” conclusion about what it means to them/actions they need to take.
How does this model relate to what you know about the use of visuals in group processes?



1 comment:
Hey there this is kind of of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML. I'm starting a blog soon but have no coding know-how so I wanted to get advice from someone with experience. Any help would be greatly appreciated! aol email login
Post a Comment